







We present Kandinsky 3.0, a large-scale text-to-image generation model based on latent diffusion, continuing the series of text-to-image Kandinsky models and reflecting our progress to achieve higher quality and realism of image generation. Compared to previous versions of Kandinsky 2.x, Kandinsky 3.0 leverages a two times larger UNet backbone, a ten times larger text encoder and remove diffusion mapping. We describe the architecture of the model, the data collection procedure, the training technique, the production system of user interaction. We focus on the key components that, as we have identified as a result of a large number of experiments, had the most significant impact on improving the quality of our model in comparison with the other ones. By results of our side by side comparisons Kandinsky become better in text understanding and works better on specific domains.
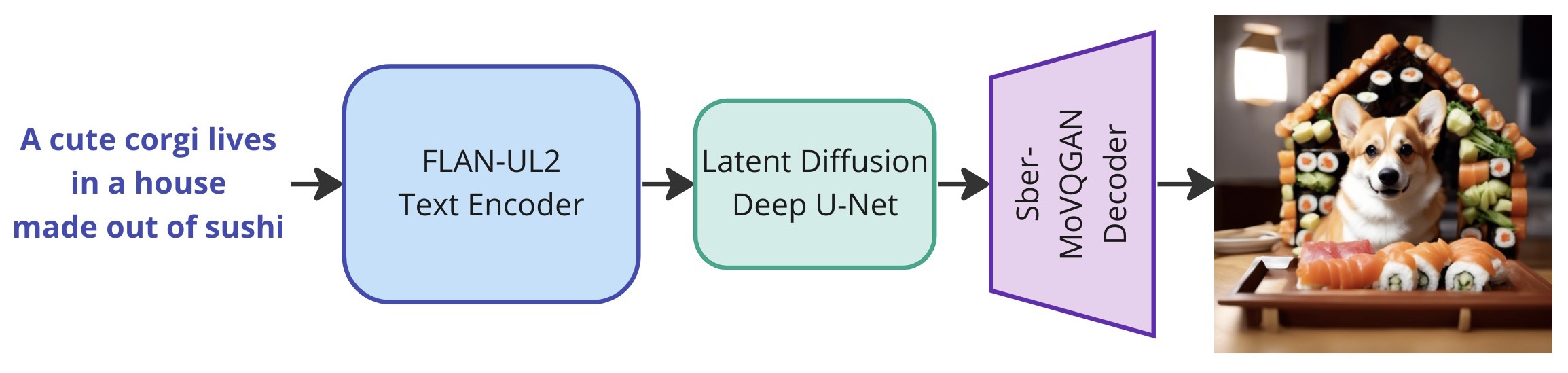
Kandinsky 3.0 is a latent diffusion model, the full pipeline of which includes a text encoder for processing a prompt from the user, a U-Net for predicting noise during denoising (reverse) process and a decoder for image reconstruction from the generated latent. During the U-Net training, the text encoder and image decoder were completely frozen. The whole model contains 11.9 billion parameters. For extended description of architecture please refer to technical report.
With our text-to-image model we additionally release an inpainting mode. Starting training from the base model, then we fine-tune it on a diverse dataset containing random masks. The model showcases its ability to intelligently fill in missing areas of images based on text query and seamlessly blending them with the surrounding visual content.




Also, our model is able to solve image completion problem naturally filling the missing areas of the image based on text and keeping it consistent with the visual context.




| Mode: "Zoom-In" Prompt: "abyss in the phone, bright image, artstation" |
Mode: "Zoom-Out" Prompt: : "big eye on the wall, a crown on it, patterns" |
| Mode: "Live" Prompt: "Christmas tree, next to it on a stump a live snowball with a cartoon face a winterlandscape in the evening" |
Mode: "Sinus" Prompt: "chinese dragon under clouds, anime" |
@misc{arkhipkin2023kandinsky,
title={Kandinsky 3.0 Technical Report},
author={Vladimir Arkhipkin and Andrei Filatov and Viacheslav Vasilev and Anastasia Maltseva and Said Azizov and Igor Pavlov and Julia Agafonova and Andrey Kuznetsov and Denis Dimitrov},
year={2023},
eprint={2312.03511},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
