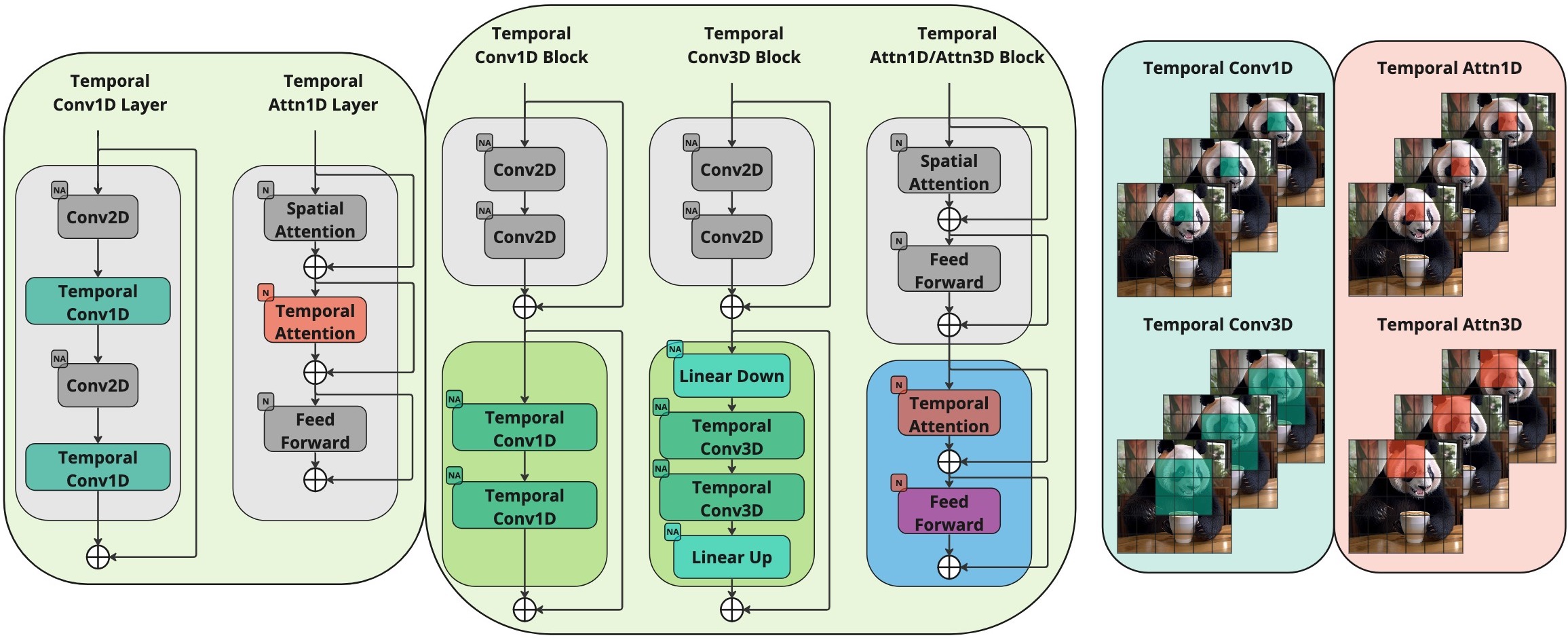
Kandinsky Video is a text-to-video generation model, which is based on the FusionFrames architecture and Kandinsky 3.0 text-to-image model, consisting of two main stages - keyframe generation and interpolation. Our approach for temporal conditioning allows us to generate videos with high-quality appearance, smoothness and dynamics.